Full text
DOI
Share
|
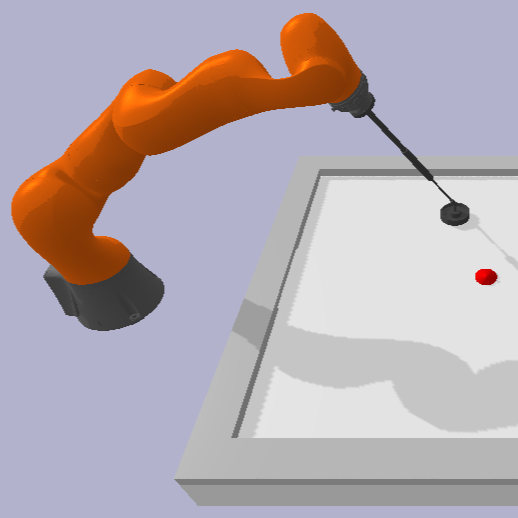
AbstractReinforcement Learning (RL) has demonstrated remarkable success across various domains. Nonetheless, a significant challenge in RL is to ensure safety, particularly when deploying it in safety-critical applications such as robotics and autonomous driving. In this work, we develop a robust and safe RL methodology grounded in manifold space. Initially, we construct a constrained manifold space, taking safety constraints into consideration. We then propose a robust safe RL approach, supported by theoretical analysis, based on the value at risk and conditional value at risk, in order to enhance the robustness of safety. Our methodology is designed to ensure safety within stochastic constraint environments. Following the theoretical analysis, we develop a practical, safe algorithm to search for a robust safe policy on stochastic constraint manifolds (ROSCOM). We evaluate the effectiveness of our approach through circular motion and air-hockey tasks. Our experiments demonstrate that ROSCOM outperforms existing baselines in terms of both reward and safety. Note to Practitioners —Real-world applications often involve inherent uncertainties, noise, and high-dimensional spaces. This complexity accentuates the urgency and challenge of ensuring safety in robot learning, especially when implementing RL in practical environments. To address this critical issue, we build a stochastic constraint manifold to delineate the safety space, thus establishing a rigorous framework for robot learning at each iteration. Compared with state-of-the-art baselines, our method can provide remarkable performance regarding safety and reward performance. For example, in an air hockey robot learning task, our method has demonstrated a remarkable 50\% enhancement in safety performance compared to the ATACOM framework, while concurrently exhibiting superior reward performance. Moreover, in contrast to traditional algorithms, including CPO, PCPO, our method has achieved a 99\% improvement in safety performance, coupled with significantly superior reward performance. These empirical insights render our approach not only theoretically sound but also practically efficacious, indicating its potential as a useful tool in real robot learning and beyond. |